From Blogger to Hakyll
Hakyll is an amazing static site generator
written in Haskell, it allows for blog posts to be written in markdown and
then compiled with pandoc. It’s very well suited to be used with GitHub
pages. It’s everything I wanted and more.
Silly Bytes went through its first 5 years of
existence hosted on Google’s Blogger service, and it
did well. Although Blogger offers a fair amount of flexibility, you can’t have
total control over it, and having to write posts with the built-in WYSIWYG
interface or pasting the HTML output is the biggest pain point of it. I solved
most of that by writing a CLI
tool
that allows me to write posts offline in markdown, compile them, and deploy
them from the terminal leveraging Blogger’s API. But that’s still too much of a
flex.
In this post I’ll describe the process of porting an existing Blogger blog to
Hakyll and GitHub pages using Silly Bytes itself as a case study.
Expectations
So here is what I want instead:
Completely port Silly Bytes to Hakyll and GitHub pages. Write every
post in markdown only, and have them automatically generated.
Further customize the design. While I’ve managed to get pretty far with
Blogger’s custom CSS option, there are still some aspects that doesn’t quite fit
what I want.
Preserve all the links to previous posts.
The initial setup
We’ll strive to keep the old blog completely functional till the last moment
when we finally change where the domain name points to.
GitHub page
The GitHub pages naming
convections
state that, in order to create a dedicated repo for a personal or organizational
page, we must have a repository named user.github.io or
organization.github.io respectively, this way GitHub will read and serve any
index file in the repository root; This supposes a problem though, We want to
keep our generated site inside a directory to keep compiled files separated from
the sources.
There are a couple of solutions for this, but they all use some Git branches
trickery, juggling with a CI service, or both; It feels way to hacky to me, not
saying that my solution is better, but it just fits better with the work flow
I’m looking for.
GitHub pages offers project specific pages as well, those are served from a
dedicated docs directory on it, so this is what we’re going to use instead.
I’ve created a sillybytes
repository in the sillybytes
organization. Then in settings → GitHub Pages → Source I’ve selected
master branch /docs folder as the page source.
Hakyll site
For the content of that repository, this will create the initial Hakyll
scaffolding:
$ hakyll-init sillybytes
$ cd sillybytes
$ stack init
$ stack build
By default, Hakyll outputs the generated site in a _site directory, but
GitHub pages will read the site from a docs directory, so let’s fix that by
editing the site.hs file.
The main function in site.hs uses the hakyll function with the default
configuration, so we need to swap that with a custom one:
main = hakyllWith config $ do
...
...
config :: Configuration
config = Configuration
{ destinationDirectory = "docs"
, storeDirectory = "_cache"
, tmpDirectory = "_cache/tmp"
, providerDirectory = "."
, ignoreFile = ignoreFile'
, deployCommand = "echo 'No deploy command specified' && exit 1"
, deploySite = system . deployCommand
, inMemoryCache = True
, previewHost = "127.0.0.1"
, previewPort = 8000
}
where
ignoreFile' path
| "." `isPrefixOf` fileName = True
| "#" `isPrefixOf` fileName = True
| "~" `isSuffixOf` fileName = True
| ".swp" `isSuffixOf` fileName = True
| otherwise = False
where
fileName = takeFileName path
Here I’ve pretty much left the default configuration intact and only changed the
destinationDirectory field to be docs.
Now recompile and regenerate the site:
$ stack build
$ stack exec site rebuild
And the generated site will now be on docs.
Deploying
The deployment process consists of regenerating the site:
$ stack exec site rebuild
Committing the changes on docs:
$ git add docs
$ git commit -m "Build"
And pushing:
$ git push origin master
No need for esoteric spells here.
Don’t shatter my links!
It is imperative to preserve the links to previous posts that were originally
published on Blogger, so they keep pointing to the right post.
Preserve legacy paths
Blogger paths convention is as follows:
Every post is on the corresponding year and month of publication name space
like year/month/post.html. So we must preserve this structure at least for the
legacy posts.
In order to achieve this keep a legacy directory inside posts, that will in
turn contain a directory tree for every year and month when posts exist.
sillybytes/posts/legacy
|
+---2012
| |
| +----01
| | +---- post.md
| |
| +----02
| |
| +---- ...
|
|
+---2013
| |
| +----01
| |
| +----02
| |
| +---- ...
|
|
+--- ...
|
+----01
|
+----02
|
+---- ...
Then we need an additional rule in site.hs
match "posts/legacy/**" $ do
route $ customRoute $ (flip replaceExtension "html") . joinPath
. (drop 2) . splitPath . toFilePath
compile $ pandocCompiler
>>= saveSnapshot "content"
>>= loadAndApplyTemplate "templates/post.html" postCtx
>>= loadAndApplyTemplate "templates/default.html" postCtx
>>= relativizeUrls
This will ensure that the year/month/post.html directory structure is
preserved on the resulting generated site.
Port legacy posts
From here, a pretty much manual porting process is required. Most of the legacy
posts were originally published right in the Blogger interface, so some rewrite
to markdow is needed.
The porting process is as follows:
- Visit the legacy post and copy the trailing name of it from the URL.
- Create the appropriate directory structure inside
posts/legacy to preserve
the same year/month/post.html path.
- Create a markdown file with the same name as it appears in the URL, but
with the
.md extension.
- Create a dedicated directory for the post inside the
images directory and
put all the post images in it.
- Paste and format the post content in the markdown file.
Any newer posts that are created after the porting can live in the posts
directory, there is no need to keep the year/month/post.html scheme any more.
The migration
The only thing left is the actual migration by pointing the domain name to the
new site.
At this point a bigger problem arises. Given that we are serving the blog from
sillybytes/docs we’ll need a URL Redirect record pointing to
sillybytes.github.io/sillybytes rather than a CNAME to just
sillybytes.github.io. If you’re fine with that, then you’re done.
I really wanted a proper CNAME record though, so I had to change the setup a
bit:
- Have two repositories:
sillybytes for the sources, and
sillybytes.github.io for the generated page.
- A deployment consists of copying the content of the
docs directory to the
sillybytes.github.io repository.
- Point the domain name with a CNAME record to
sillybytes.github.io.
New CLI tool
The CLI tool I was using before
for Blogger deployment is no longer useful, but I can still adapt it to the new
deployment schema:
cp -rfv _site/* ../sillybytes.github.io/
cd ../sillybytes.github.io
display_info "Deploying..."
git add .
git commit -m "Deploy"
git push origin master
display_success "Deployed!"
As well as aliasing common Hakyll commands:
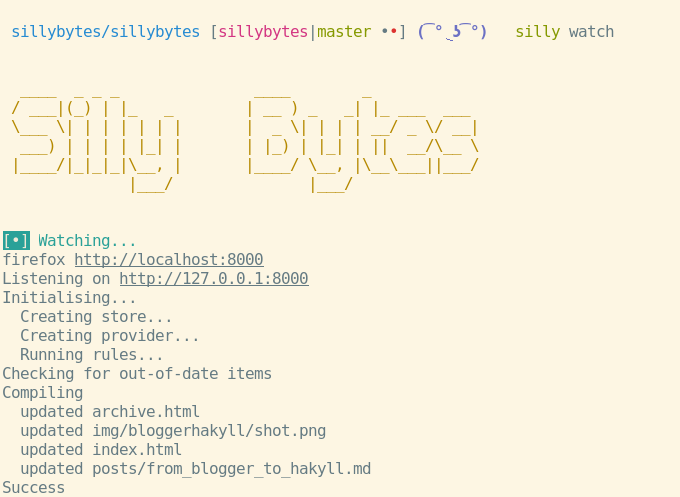
That’s some comfy blogging right there.
Hakyll is an amazing static site generator written in Haskell, it allows for blog posts to be written in markdown and then compiled with pandoc. It’s very well suited to be used with GitHub pages. It’s everything I wanted and more.
Silly Bytes went through its first 5 years of existence hosted on Google’s Blogger service, and it did well. Although Blogger offers a fair amount of flexibility, you can’t have total control over it, and having to write posts with the built-in WYSIWYG interface or pasting the HTML output is the biggest pain point of it. I solved most of that by writing a CLI tool that allows me to write posts offline in markdown, compile them, and deploy them from the terminal leveraging Blogger’s API. But that’s still too much of a flex.
In this post I’ll describe the process of porting an existing Blogger blog to Hakyll and GitHub pages using Silly Bytes itself as a case study.
Expectations
So here is what I want instead:
Completely port Silly Bytes to Hakyll and GitHub pages. Write every post in markdown only, and have them automatically generated.
Further customize the design. While I’ve managed to get pretty far with Blogger’s custom CSS option, there are still some aspects that doesn’t quite fit what I want.
Preserve all the links to previous posts.
The initial setup
We’ll strive to keep the old blog completely functional till the last moment when we finally change where the domain name points to.
GitHub page
The GitHub pages naming
convections
state that, in order to create a dedicated repo for a personal or organizational
page, we must have a repository named user.github.io or
organization.github.io respectively, this way GitHub will read and serve any
index file in the repository root; This supposes a problem though, We want to
keep our generated site inside a directory to keep compiled files separated from
the sources.
There are a couple of solutions for this, but they all use some Git branches trickery, juggling with a CI service, or both; It feels way to hacky to me, not saying that my solution is better, but it just fits better with the work flow I’m looking for.
GitHub pages offers project specific pages as well, those are served from a
dedicated docs directory on it, so this is what we’re going to use instead.
I’ve created a sillybytes
repository in the sillybytes
organization. Then in settings → GitHub Pages → Source I’ve selected
master branch /docs folder as the page source.
Hakyll site
For the content of that repository, this will create the initial Hakyll scaffolding:
$ hakyll-init sillybytes
$ cd sillybytes
$ stack init
$ stack buildBy default, Hakyll outputs the generated site in a _site directory, but
GitHub pages will read the site from a docs directory, so let’s fix that by
editing the site.hs file.
The main function in site.hs uses the hakyll function with the default
configuration, so we need to swap that with a custom one:
main = hakyllWith config $ do
...
...
config :: Configuration
config = Configuration
{ destinationDirectory = "docs"
, storeDirectory = "_cache"
, tmpDirectory = "_cache/tmp"
, providerDirectory = "."
, ignoreFile = ignoreFile'
, deployCommand = "echo 'No deploy command specified' && exit 1"
, deploySite = system . deployCommand
, inMemoryCache = True
, previewHost = "127.0.0.1"
, previewPort = 8000
}
where
ignoreFile' path
| "." `isPrefixOf` fileName = True
| "#" `isPrefixOf` fileName = True
| "~" `isSuffixOf` fileName = True
| ".swp" `isSuffixOf` fileName = True
| otherwise = False
where
fileName = takeFileName pathHere I’ve pretty much left the default configuration intact and only changed the
destinationDirectory field to be docs.
Now recompile and regenerate the site:
$ stack build
$ stack exec site rebuildAnd the generated site will now be on docs.
Deploying
The deployment process consists of regenerating the site:
$ stack exec site rebuildCommitting the changes on docs:
$ git add docs
$ git commit -m "Build"And pushing:
$ git push origin masterNo need for esoteric spells here.
Don’t shatter my links!
It is imperative to preserve the links to previous posts that were originally published on Blogger, so they keep pointing to the right post.
Preserve legacy paths
Blogger paths convention is as follows:
Every post is on the corresponding year and month of publication name space
like year/month/post.html. So we must preserve this structure at least for the
legacy posts.
In order to achieve this keep a legacy directory inside posts, that will in
turn contain a directory tree for every year and month when posts exist.
sillybytes/posts/legacy
|
+---2012
| |
| +----01
| | +---- post.md
| |
| +----02
| |
| +---- ...
|
|
+---2013
| |
| +----01
| |
| +----02
| |
| +---- ...
|
|
+--- ...
|
+----01
|
+----02
|
+---- ...Then we need an additional rule in site.hs
match "posts/legacy/**" $ do
route $ customRoute $ (flip replaceExtension "html") . joinPath
. (drop 2) . splitPath . toFilePath
compile $ pandocCompiler
>>= saveSnapshot "content"
>>= loadAndApplyTemplate "templates/post.html" postCtx
>>= loadAndApplyTemplate "templates/default.html" postCtx
>>= relativizeUrlsThis will ensure that the year/month/post.html directory structure is
preserved on the resulting generated site.
Port legacy posts
From here, a pretty much manual porting process is required. Most of the legacy posts were originally published right in the Blogger interface, so some rewrite to markdow is needed.
The porting process is as follows:
- Visit the legacy post and copy the trailing name of it from the URL.
- Create the appropriate directory structure inside
posts/legacyto preserve the sameyear/month/post.htmlpath. - Create a markdown file with the same name as it appears in the URL, but
with the
.mdextension. - Create a dedicated directory for the post inside the
imagesdirectory and put all the post images in it. - Paste and format the post content in the markdown file.
Any newer posts that are created after the porting can live in the posts
directory, there is no need to keep the year/month/post.html scheme any more.
The migration
The only thing left is the actual migration by pointing the domain name to the new site.
At this point a bigger problem arises. Given that we are serving the blog from
sillybytes/docs we’ll need a URL Redirect record pointing to
sillybytes.github.io/sillybytes rather than a CNAME to just
sillybytes.github.io. If you’re fine with that, then you’re done.
I really wanted a proper CNAME record though, so I had to change the setup a bit:
- Have two repositories:
sillybytesfor the sources, andsillybytes.github.iofor the generated page. - A deployment consists of copying the content of the
docsdirectory to thesillybytes.github.iorepository. - Point the domain name with a CNAME record to
sillybytes.github.io.
New CLI tool
The CLI tool I was using before for Blogger deployment is no longer useful, but I can still adapt it to the new deployment schema:
cp -rfv _site/* ../sillybytes.github.io/
cd ../sillybytes.github.io
display_info "Deploying..."
git add .
git commit -m "Deploy"
git push origin master
display_success "Deployed!"As well as aliasing common Hakyll commands:
That’s some comfy blogging right there.